


Apache Iceberg Community Newsletter: What Happens on Tour Edition
Tabular is acquired for HOW MUCH?!, Intel misses the deal of the decade, and geeks talked all things Apache Iceberg at a brewery in San Francisco 🍻

Mouths gaped open across the industry this week when news started circulating that Databricks, who recently acquired Tabular, actually paid nearly $2B for the company,—and not the $1B first reported. The valuation was based on Tabular’s tie-in with Iceberg, leading it to become the ultimate prize in a tug of war between Databricks and its competitor, Snowflake. The shock of the acquisition cost came less from the amount, and more from the fact that Tabular’s annual recurring revenue (ARR) amounted to around $1M.
While the fortunes of Tabular’s shareholders has been fortuitous [and enviable!—Ed], things are not so rosy in the Intel boardroom. The chipmaker, who dominated the market for decades, turned down an offer to buy shares in OpenAI back in 2017. OpenAI courted Intel for investment to reduce their reliance on Nvidia, but Intel passed, not foreseeing the rise of AI. This inaccurate forecasting has been to Intel’s expense as their stock lost 58% of its value this year. Ouch!
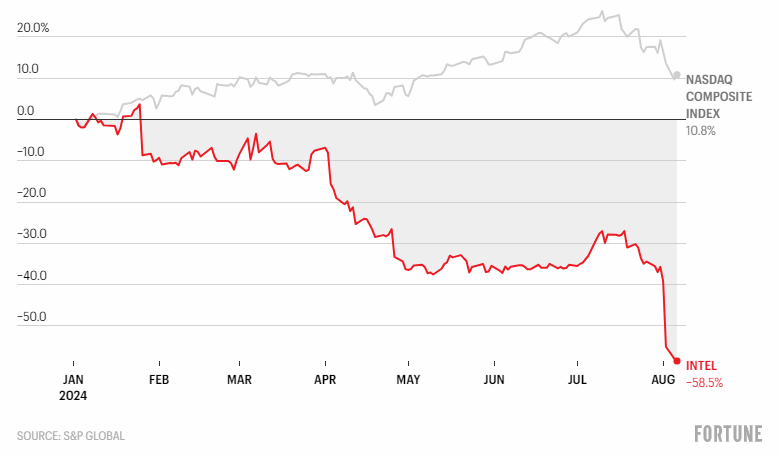
Meanwhile, Nvidia made more accurate predictions for AI, becoming the world’s most valuable company at $3 trillion. Market experts expect this to double by the end of 2024! 😲
Back to reality for the rest of us… the first stop of our Chill Data Summit on tour went off with a bang, when we hosted our kick-off Iceberg event at the Devil’s Canyon Brewing Company in San Francisco. Our lucky attendees enjoyed talks from Julien Le Dem, Jacques Nadeau, and Lisa N. Cao, followed by hands-on training from Holden Karau, where they built a production-grade Iceberg lakehouse. Awesome!





With so much information out there, it can be hard to know where to start your learning. This is why we structured our free events to ease you in gently, but return you to work with practical skills to impress your boss 👌
If you missed out, you can still register to join us in London on September 17th, or New York or Tel Aviv in October. This is an amazing opportunity to learn Iceberg from the ground up [that feels like the wrong metaphor - Ed], and in a community-led, supportive space.
👋 Call for papers is open for CDS on tour: please submit your talk through this form.
🗞️ Industry News
The latest news and updates from the data industry.
Polaris Catalog is Now an Official Apache Incubating Project
Polaris, the interoperable, open source catalog for Apache Iceberg, has officially been accepted as an Apache Incubating project, marking a significant milestone in its development. Under the stewardship of the Apache Software Foundation, Polaris Catalog aims to streamline data discovery, governance, and cataloging for organizations leveraging large-scale data ecosystems.
This transition into the Apache Incubator signifies broader community support, heightened visibility, and a commitment to open development practices, setting the stage for Polaris Catalog to become a leading tool in the data management market.
Iceberg Alert? Snowflake Losses Widen, But it's Not All Bad News
Snowflake reported a $317 million loss in Q2 despite a 30% increase in product revenues, driven partly by increased spending on compute for AI features. The company highlighted the strong adoption of its new Iceberg Tables, with 400 customers using the feature.
Despite competition, especially from Databricks' acquisition of Tabular, Snowflake's CEO emphasized the importance of Iceberg in the industry and reiterated their commitment to security following recent customer data breaches. Additionally, Snowflake launched Snowpark Container Services on AWS, enabling serverless, managed applications within its platform.
Crunchy Data Brings Iceberg to Managed Postgres
Crunchy Data, a provider of open-source Postgres technologies and products, recently announced support for querying Apache Iceberg tables directly from Postgres in its latest release of Crunchy Bridge for Analytics.
“Native querying of Iceberg files further extends the value of Crunchy Bridge’s growing analytics capabilities,” said Craig Kerstiens, Crunchy Data Chief Product Officer. “The ability to natively query data like Iceberg tables or Parquet files where they live is an exciting advancement.”
📑 Articles
Discover the hottest topics and discussions in the data engineering world.
Why Apache Iceberg Will Rule Data in the Cloud
James Malone, Head of Data Storage and Engineering at Snowflake, discusses the impact of cloud storage on data management, emphasizing challenges like schema changes and query difficulties in traditional systems. James highlights the advantages of applying the Apache Iceberg open table format, which offers benefits like schema evolution, time-travel queries, and ACID compliance.

Iceberg's design, free from legacy issues, offers flexibility by supporting various processing engines and file formats. The project’s strong open-source community, managed by the Apache Software Foundation, is driving innovation and collaboration, making Iceberg a robust choice for modern data architectures.
Iceberg vs Hudi — Benchmarking Table Formats
This article explores Flipkart’s benchmarking exercise, comparing the performance of prominent table formats: Hudi and Iceberg. It analyzes high-level results observed for various benchmarking profiles, and provides insights into how data characteristics influence the optimal choice of table format.
Although Flipkart went ahead with Iceberg as the table format of its choice, this article compares performance between Hudi and Iceberg for different use cases.
Understanding Apache Iceberg's Consistency Model Part 1
This article from Jack Vanlightly provides a seriously in-depth look at Apache Iceberg's consistency model and internal mechanics. It begins by explaining Iceberg's file structure, which includes metadata and data layers stored in object stores.
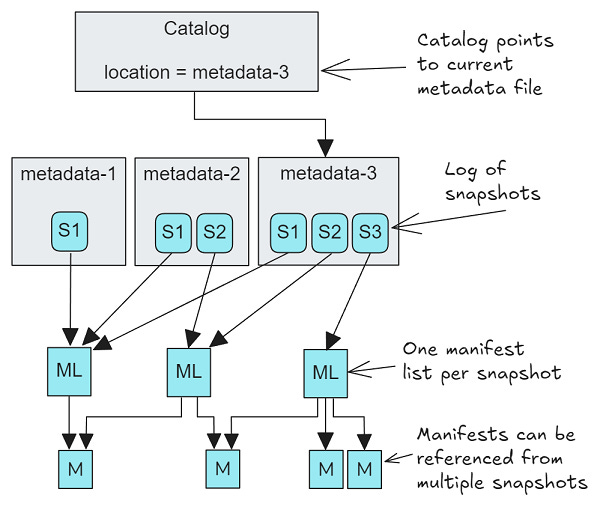
Using plenty of visuals, Jack explains how Iceberg manages table versions through snapshots, using a tree-like structure of manifest-list files, manifest files, and data files. Furthermore, he explores Iceberg's commit process, which uses an atomic compare-and-swap operation against a catalog.
Iceberg 101: A Guide to Iceberg Partitioning
One of the most interesting innovations in Apache Iceberg is its approach to partitioning. As organizations grapple with ever-growing datasets, understanding and implementing efficient partitioning strategies becomes crucial for optimizing query performance and storage costs.

Learn how it’s done in Iceberg natively, which parts are automated (and which aren’t), and how to ensure you squeeze every last bit of performance from your Iceberg tables.
🎙️Podcasts & Videos
Grab your headphones and catch up on the latest news, opinions, and highlights from some of the industry’s leading pioneers and voices in technology.
Apache Hudi Vs Apache Iceberg
The Data Guy, aka George Yates, compares two of the most popular formats for big data lakes, covering how they work, their best/worst use cases, and respective advantages.
George will help you decide if you need Hudi, Iceberg, or both, and explores how each handles schema evolution, partitioning and indexing, data consistency, performance, and scalability.
What is a Data Lakehouse?
Sean Falconer chats with Ori Rafael, CEO and Co-founder of Upsolver, to explore the rise of the lakehouse architecture and its significance in modern data management. Ori breaks down the origins of the lakehouse and how it leverages S3 to provide scalable and cost-effective storage.

Sean and Ori discuss the critical role of open table formats like Apache Iceberg in unifying data lakes and warehouses, and how ETL processes differ between these environments.
Open Data Engineering Q&A
Zach Wilson hosts his regular live Q&A session where data engineers and professionals pose technical and career questions. This call includes questions to ask an interviewee, should you convert your monolith into many microservices, how to start in data science, testing the quality of data transformations, and why there’s a lack of data engineering jobs… Plus loads more!
Snowflake vs Databricks - And the Battle For Iceberg
Join the Seattle Data Guy in asking: can enterprises build a single data layer that behaves like a data warehouse using a standardized storage system, or will company politics, regulations, or highly opinionated team members get in the way of this ideal data landscape?

🗓️ Upcoming Events
Don’t miss out on the opportunity to expand your knowledge and network with your peers in a community environment.
Data Engineering Coffee Chat ☕
London | August 24, 2024, 2 PM (BST)
Join the London Data Engineer Group for a discussion on leveraging AWS, Azure, and GCP for data engineering. This meetup covers data analytics, machine learning, and software engineering in the cloud, making it ideal for both beginners and those looking to expand their skills.
This is your chance to network with fellow data engineers and stay updated on the latest cloud technologies for data projects.
Data Archiving Techniques with PySpark & Iceberg
Online | August 27, 2024 | 6.30 PM (GMT)
Join this tech talk with Antonello Benedetto, Lead Data Engineer at Wise, on advanced data archiving using PySpark and Iceberg. You'll learn how to design and implement archiving solutions, explore the benefits and challenges of using Airflow, AWS EMR, and Iceberg, and gain insights from real-world projects.
Iceberg Community Sync
Online | September 11, 2024 | 11 AM EST / 4 PM (GMT)
Hosted every three weeks on a Wednesday, this Iceberg meeting is for anyone wanting to get involved in the Iceberg development or documentation, or simply learn about the roadmap.
Apache Iceberg Roadshow
London | September 16, 2024 | 9 AM BST
Join experts from AWS for an immersive exploration of Apache Iceberg, the open table format transforming big data analytics. This comprehensive event offers a blend of market business insights, technical deep dives, and practical hands-on experience.
✨ Chill Data Summit London ✨
London | September 17, 2024 | 9 AM BST
The Chill Data Summit is an exciting opportunity to learn Apache Iceberg from project committers and industry users. Featuring talks, hands-on workshops, and networking—all in a non-commercial, collaborative environment.

In addition to keynotes from experts, get hands-on training from distinguished engineers to build an optimized, production-grade Iceberg lakehouse to support your business use cases.
Next month we’ll be in London, followed by New York and Tel Aviv. Reserve your place 👇
Big Data London
London | September 18-19, 2024
This two-day event is a hub for the data community to learn best practices, build relationships, and find the tools to develop an effective data-driven business.

🎥 Event Replays
This year has already been packed with lakehouse events and presentations, so here are a few you might have missed. Grab a ☕and enjoy some free learning.
Automated Optimization for Apache Iceberg Tables
Watch the replay of the AWS team live on air at the New York Summit 2024, discussing how AWS Glue Data Catalog keeps your transactional data lakes storage optimized by automatically removing data files that are no longer needed and running compactions of Apache Iceberg tables.
Getting Started with Polaris Catalog and Iceberg Tables
Polaris Catalog is an open-source catalog for Apache Iceberg that maximizes organizations ability to achieve interoperability between different engines, minimizing complexity and storage costs while avoiding vendor lock-in.
In this recorded hands-on tutorial, you will learn the essentials of setting up, ingesting, and querying an Iceberg-based lakehouse using the Polaris Catalog on Snowflake.
👋 Share Your News
Want your Apache Iceberg news or event to be featured in our next newsletter? Then we’d love to hear from you. DM us with the details and we’ll be in touch.
For this monthly newsletter and other Chill Data Summit community posts, subscribe!