


Apache Iceberg Community News: You Couldn't Make it Up Edition
Year of the Iceberg, S3 turns 18, and S3 Tables and S3 Metadata are launched.

This year has been transformative for the tech industry, with Apache Iceberg taking center stage as a critical technology for modern data architecture. The acquisition of Tabular by Databricks highlighted the growing importance of Iceberg in enabling efficient data lakehouse solutions.
Many companies, including AWS, Microsoft, Snowflake, Upsolver, and Dremio, have continued to expand their support for Iceberg, contributing to its rapid adoption by businesses needing a more progressive and interoperable solution than a data lake. These developments underscore Iceberg's role in shaping the future of data management, with its open standards and advanced capabilities driving innovation and collaboration at an unprecedented pace.
This year was monumental for our community as we launched 2024 in style with the first Chill Data Summit in NYC! The event brought together an incredible line-up of speakers, including Ryan Blue, Benn Stancil, Joe Reis, Matt Housley, and many more. But we didn’t stop there—our CDS journey turned into a tour, hitting San Francisco, and London, and even making a triumphant return to NYC before wrapping up in Tel Aviv. Each stop brought fresh insights, new connections, and unforgettable moments, making it a year to remember! ⭐
The tech industry is not ending the year quietly either. At last week’s AWS re:Invent, Amazon celebrated S3’s 18th birthday by announcing S3 Table buckets and S3 Metadata. Optimized for Apache Iceberg, S3 Tables offer speedy performance for analytics workloads, while S3 Metadata indexes metadata so you can use SQL-like queries for data discovery. More on this below.
Meanwhile, over at Microsoft HQ, it feels like their 2024 dramas distracted from the positive news from Redmond. Following the Crowdstrike outage causing 8.5M Windows computers to display the BSOD, Microsoft went on to release a Windows 11 update that wreaked havoc, and was described by PC Gamer as “a full-on borkfest”. Then, a Windows Server security update was mis-labeled and turned out to be a full upgrade to Windows Server 2025. This would not have been so bad, only, it self-installed itself in server rooms worldwide.
If there are parts of your working day (such as self-installing OS upgrades) that you want to forget, that’s fine because Microsoft has the perfect solution. Launched this year, Windows Recall takes a regular snapshot of your screen so you can remember what you were doing every minute. Recall was released and rapidly withdrawn because it was not saving consistent snapshots and leaving memory gaps.🤦

I’m hoping an engineer at Microsoft is secretly in the throws of scripting a version of the UK sitcom, The IT Crowd, loosely based on the events that happened this year, because it feels like one of those years where you really couldn’t have made it up.
Anyway, wherever and however you’re celebrating the festive season, have a good one!
To be continued…
🗞️ Industry News
The latest news and updates from the data industry.
AWS Introduces S3 Tables, a New Bucket Type for Data Analytics
At AWS re:Invent, two major updates were announced for Amazon S3: the introduction of S3 Table buckets and a new S3 Metadata feature. S3 Tables are optimized for Apache Iceberg, offering up to 10x performance improvements by automating table maintenance and pre-partitioning data, making it ideal for large-scale analytics.
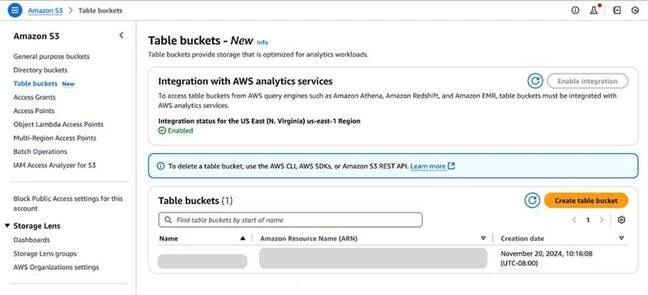
The new S3 Metadata feature, currently in preview, enables SQL-like queries for data discovery by indexing metadata into S3 Tables. These updates integrate with AWS Glue and Lake Formation, streamlining data management while maintaining compatibility with existing tools like Amazon Athena.
AI and Analytics Converge in New Generation Amazon SageMaker
Amazon unveiled the next generation of SageMaker at AWS re:Invent, highlighting its interoperability with Apache Iceberg through the new SageMaker Lakehouse. Lakehouse integrates data from S3 and Redshift and enables SQL queries using tools like Athena or Spark, allowing seamless analytics and machine learning workflows.
Unified Studio, a centrepiece of the updated platform, provides an end-to-end environment for analytics, ML, and generative AI development, leveraging the same Iceberg-backed data for these converging workloads. This integration streamlines data access and management, addressing challenges in finding and utilizing enterprise data efficiently. SageMaker’s expanded capabilities cater to developers while maintaining compatibility with analytics and business intelligence tools like Quicksight.
9 Notable Innovations from AWS CEO Matt Garman’s re:Invent Keynote
At AWS re:Invent, CEO Matt Garman delivered a three-hour keynote to an audience of 60,000 in Las Vegas and 400,000 online. Garman, who became CEO earlier this year after joining AWS in 2006, addressed the builder and developer-focused conference, which featured 1,900 sessions and 3,500 speakers, including AWS experts, partners, and customers.

Garman’s keynote highlighted nine major innovations aimed at streamlining developer workflows and boosting productivity, reaffirming AWS’s commitment to empowering its community.
📑 Articles
Discover the hottest topics and discussions in the data engineering world.
AWS S3 Tables and the Race for Managed Storage
Roy Hasson, VP of Product at Upsolver, introduces us to AWS S3 Tables, a new type of bucket designed to simplify managing tabular data using Apache Iceberg. Roy explores the core features of S3 Tables, including a built-in, managed catalog that supports Iceberg table operations with specific APIs and namespaces.
A unique Table Bucket resource automates bucket creation and optimizes performance, and managed optimization features support table maintenance tasks like compaction and snapshot expiration. While S3 Tables integrates well with AWS analytics services through Glue Data Catalog, proprietary APIs and design choices may hinder broader adoption. Despite potential benefits, the solution faces some core challenges, so read on to find out more.
2025 Guide to Architecting an Iceberg Lakehouse
Alex Merced created this guide to help you work through the questions you need to ask yourself before architecting an Apache Iceberg lakehouse. Alex has segmented the questions so you can thoroughly think through all the considerations upfront. Yes, there is a lot to chew over, but knowing the answers - or at least the questions that will arise when you get started - will prepare you. It is worth devoting the time to work through each question before you dive too deep into the lakehouse.
Apache Iceberg Quickstart with PyIceberg
In this hands-on guide, Dunith Danushka, Senior Developer Advocate at Redpanda Data, explores Apache Iceberg through PyIceberg, its official Python client. Dunith covers how to set up a local Iceberg catalog using SQLite, create and populate an Iceberg table with NYC taxi data with Python, and work with the PyIceberg CLI.
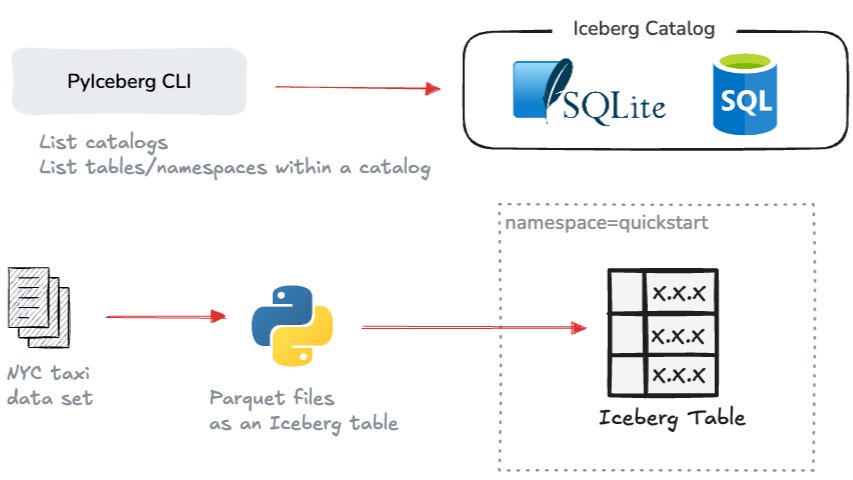
The article will help you begin your Iceberg hands-on journey without getting into the complexities of setting up object stores and query engines. Everything is done with Python while covering the essentials.
Performing DML Operations on Apache Iceberg 🧊 Tables in Jupyter Notebook with MinIO
Apache Iceberg is a powerful table format for managing large-scale datasets, providing features like schema evolution, time travel, and efficient partitioning. When combined with MinIO for object storage and Jupyter Notebook as a development environment, Iceberg becomes a robust solution for data engineering workflows.
In this article, Sameer Shaik focuses on performing Data Manipulation Language (DML) operations—such as inserting, updating, deleting, querying, and merging data—on Iceberg tables using Jupyter Notebook with MinIO as the storage backend. By walking through practical examples, this guide demonstrates how to set up your environment and execute these operations effectively in a notebook setting.
🎙️Podcasts & Videos
Discover the hottest topics and discussions in the data engineering world.
Apache Iceberg Lakehouse Engineering Podcast
Check out this playlist of hands-on videos from Alex Merced, to help you understand the Apache Iceberg based data lakehouse. Learn the basic concepts for moving from a data lake to lakehouse architecture, how to set up Spark and Jupyter Notebooks on your laptop, ingesting data to Iceberg, working with Iceberg tables using the Filesystem catalog in Hadoop, and lots more!

Spark + Iceberg in 1 Hour - Memory Tuning, Joins, Partition
Jump right into Day 1, Week 3 of the free data engineering boot camp with Zach Wilson, running live until the end of 2024. Including a hands-on lab, Zach runs through the Apache Spark basics, including architecture, the roles of the Driver and Executor, and how it all comes together. Also the all-important question of when to choose Spark over an alternative tool.
If you can dedicate some time during the festive season to watching this series, it’s well worth the investment to level up your skills or fill in any gaps in your knowledge. Happy learning, folks!
Reacting to the AWS re:Invent Keynote
Join Brian Gracely, co-host of The Cloudcast, in conversation with Brandon Whichard, to review their top takeaways from the many announcements and product updates that came out of this year’s AWS re:Invent.
🗓️ Upcoming Events
Don’t miss out on these events taking place in the next few months, for the opportunity to expand your knowledge and network.
Data Day Texas, 2025
Austin, Texas | January 25, 2025 | 8 AM - 6 PM CST
This amazing data event is returning to Texas for 2025 and you’d be mad to miss out the incredible line-up of speakers and topics on offer. Ole Olesen-Bagneux, O'Reilly author, creator of Meta Grid, and podcast host, will kick off proceedings with a Metadata Keynote, and Bethany Lyons will host a deep dive into automating financial reconciliation with linear programming and optimization.

Also part of the speaker line-up are Chill Data Summit speakers, Joe Reis, Lisa Cau, Ryan Dolley, Chris Tabb, and Matthew Housley, and more! Go check out the rest, and be sure to register your ticket!
Apache Iceberg Bay Area Community Meetup
AWS Palo Alto & Virtual | January 30, 2025
Join this special edition of the Apache Iceberg Bay Area Meetup—a half-day event co-hosted by PuppyGraph, Snowflake, AWS, Databricks, and the Apache Iceberg Community! This event offers both in-person attendance and virtual streaming, making it accessible to everyone, with an agenda packed with the latest innovations and best practices in the Apache Iceberg ecosystem.

The January session features four hours of insightful talks and networking sessions, with festive food and beverages. Can't make it live? No worries—register anyway to receive the recordings. Don't miss this opportunity to engage with the Apache Iceberg community and stay updated on the latest advancements.
Winter Data Conference 2025
Austria | March 7, 2025
The Winter Data Conference combines learning with Alpine fun! Experience the ultimate data immersion in the breath-taking Austrian Alps at the Zell am See Winter Data Conference!
This special event will include a full day of data-driven insights, cutting-edge discussions, and unparalleled networking opportunities, followed by cocktails and another day devoted to skiing (if you don’t have too many cocktails the night before 🍸). Enjoy talks from industry-leading data experts, including Joe Reis, author of the Fundamentals of Data Engineering.
🎥 Event Replays
This year was packed with lakehouse events and presentations, so here are a few you might have missed. Grab a ☕and enjoy some free learning.
AWS re:Invent 2024 - Dr. Werner Vogels Keynote
Watch Dr. Werner Vogels, VP and CTO at Amazon.com, as he shares the critical lessons and strategies he has learned for managing increasingly complex systems. The keynote explores the core principles for embracing complexity, drawing on Amazon’s experiences building distributed systems at massive scale.
AWS re:Invent 2024 - How Ford unlocked real-time insights using Apache Iceberg on AWS
In the era of connected vehicles, it’s crucial for automakers to use real-time, data-driven insights to enhance customer experiences and drive operational efficiencies. This session explores Ford’s collaboration with AWS to develop the Event Store, a key component of Ford’s Transportation Mobility Cloud (TMC).
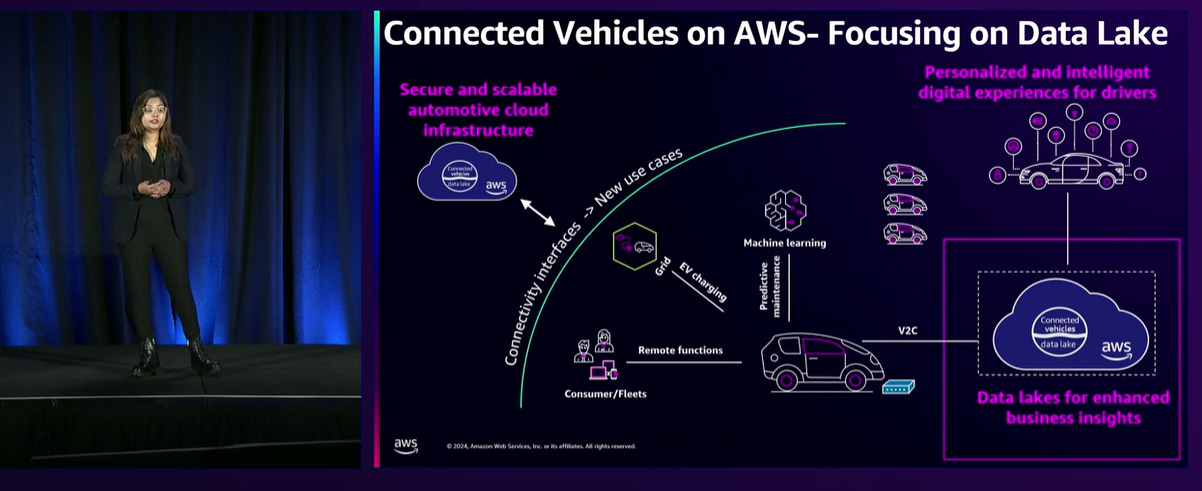
This platform processes 4 TB of real-time data daily from over 20 million vehicles, allowing insights around OTA updates, vehicle command and control, and telemetry. Ford’s strategic adoption of AWS services facilitated a petabyte-scale data lake using Apache Iceberg, improving data management and analysis and reducing SLAs by 50% while meeting low-latency requirements.
REST Catalogs in Apache Iceberg
In this insightful talk, Lisa N. Cau, a leading contributor to the data community, explores the emerging role of REST catalogs in simplifying data management in an Apache Iceberg lakehouse. With her extensive experience in building scalable data solutions, Lisa delves into how REST-based catalogs offer a flexible and accessible way to interact with metadata, making it easier to manage large-scale datasets.

Learn how REST catalogs enhance interoperability across different platforms, streamline operations, and contribute to Iceberg’s mission of delivering an open, high-performance data lakehouse architecture. Whether you're a data engineer, architect, or open-source enthusiast, Lisa’s talk offers valuable perspectives on unlocking the full potential of Apache Iceberg.
👋 Share Your News
Do you want your Apache Iceberg news or event featured in our next newsletter? We’d love to hear from you. DM us with the details, and we’ll be in touch.